
SOMA automatically transforms raw marker based mocap point clouds (black dots in the back) into labeled markers (colored dots) and solved bodies.
Abstract
Marker-based optical motion capture (mocap) is the “gold standard” method for acquiring accurate 3D human motion in computer vision, medicine, and graphics. The raw output of these systems are noisy and incomplete 3D points or short tracklets of points. To be useful, one must associate these points with corresponding markers on the captured subject; i.e. “labelling”. Given these labels, one can then “solve” for the 3D skeleton or body surface mesh. Commercial auto-labeling tools require a specific calibration procedure at capture time, which is not possible for archival data. Here we train a novel neural network called SOMA, which takes raw mocap point clouds with varying numbers of points, labels them at scale without any calibration data, independent of the capture technology, and requiring only minimal human intervention. Our key insight is that, while labeling point clouds is highly ambiguous, the 3D body provides strong constraints on the solution that can be exploited by a learning-based method. To enable learning, we generate massive training sets of simulated noisy and ground truth mocap markers animated by 3D bodies from AMASS. SOMA exploits an architecture with stacked self-attention elements to learn the spatial structure of the 3D body and an optimal transport layer to constrain the assignment (labeling) problem while rejecting outliers. We extensively evaluate SOMA both quantitatively and qualitatively. SOMA is more accurate and robust than existing state of the art research methods and can be applied where commercial systems cannot. We automatically label over 8 hours of archival mocap data across 4 different datasets captured using various technologies and output SMPL-X body models. The model and data is released for research purposes at https://soma.is.tue.mpg.de/.
1. Self-attention mechanism to process sparse deformable point cloud data.
To label a cloud of sparse 3D points, resulted from a marker based motion capture session, containing outliers and missing data, is a highly ambiguous task. Our solution exploits a transformer architecture to capture local and global contextual information using self-attetion. SOMA consumes mocap point clouds directly and outputs a distribution
over marker labels.
In the image to the left the cube shows the marker of interest and color intensity depicts the average value of attention across frames of 50 randomly selected sequences. Each column shows a different marker. At the first layer (top) we see wider attention compared to the deepest layer (bottom).
2. Training on synthetic data.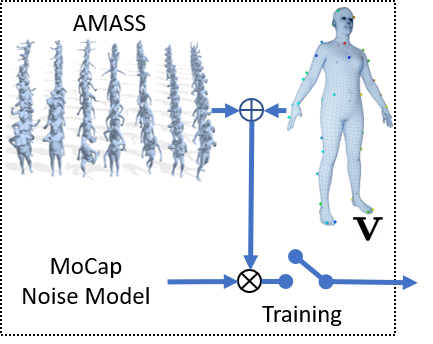
Various noise sources can influence mocap data, namely: subject body shape, motion, marker layout and the exact placement of the markers on body, occlusions, ghost points, mocap hardware intrinsics, and more. To learn a robust model, we exploit AMASS [Mahmood et al. ICCV'19] and virtual markers on these bodies following the desired marker placement. Our novel synthetic mocap generation pipeline demonstrates generalization to real mocap datasets.
SOMA offers a robust marker based mocap auto solving solution that works with archival data, different mocap
technologies, poor data quality, and varying subjects and motions.
(If the Youtube video does not play, click here to view the video.)
Paper

SOMA: Solving Optical Marker-Based MoCap Automatically
Nima Ghorbani, Michael J. Black.
ICCV 2021 (Poster Presentation)
[PDF] [Supp] [Poster] [arXiv]
BibTex
@inproceedings{SOMA:ICCV:2021,
title = {{SOMA}: Solving Optical Marker-Based MoCap Automatically},
author = {Ghorbani, Nima and Black, Michael J.},
booktitle = {Proc. International Conference on Computer Vision (ICCV)},
pages = {11117--11126},
month = oct,
year = {2021},
doi = {},
month_numeric = {10}
}
Related Projects
AMASS: Archive of Motion Capture as Surface Shapes (ICCV 2019)
Naureen Mahmood, Nima Ghorbani, Nikolaus F. Troje, Gerard Pons-Moll, Michael J. Black
AMASS is a large database of human motion unifying different optical marker-based motion capture datasets by representing them within a common framework and parameterization.
GRAB: A Dataset of Whole-Body Human Grasping of Objects (ECCV 2020)
Omid Taheri, Nima Ghorbani, Michael J. Black, Dimitrios Tzionas
GRAB is a marker-based mocap database of human bodies intracting with objects with both hands and face while the reconstructed surfaces are contact level accurate.